
Transcribing Century-Old Newspapers at The Wall Street Journal
 May 11, 2020
May 11, 2020 Leave a comment
Leave a comment
By Rahul Hayaran, Yi-Lin Chen, and Rosa Lin
The Wall Street Journal wanted to do something special for their 130th Anniversary: create a special edition, digitized broadsheet of stories from their entire history. While their archives had been well preserved and imaged, extracting the text from old — in some cases century-old — pages proved tricky. The newspaper approached Tolstoy to help them extract the text accurately — and on deadline for their 130th anniversary.
This article covers how we used the latest techniques in image processing and optical character recognition to digitize and extract the text from the newspaper broadsheets.
Primer on OCR
Optical character recognition, more commonly known as OCR, is among the foundational computer vision tasks. Basically, it is the technology that converts images of typed or handwritten text into machine-encoded text (i.e. strings).
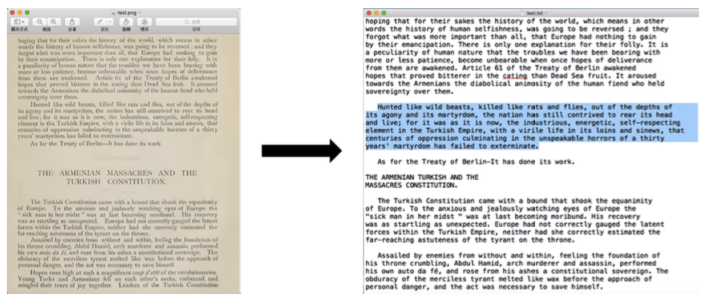
It was one of the first big machine learning problems to be tackled by researchers — chiefly because it didn’t require deep learning to achieve good performance. These days OCR is largely seen as a solved problem, especially in “domestic” settings like PDFs and scanned documents. But, there is a very long tail of cases where even paid/state-of-the-art options, such as Google Cloud Vision and Amazon Textract (not to mention the very good open-source Tesseract), fail.

You see, most OCR, by default, reads text from left-to-right and top-to-bottom — in that order. While this is well suited to most essays, novels, contracts, and official documents (what largely comprised the training sets of early OCR), it isn’t so conducive to a lot of other real world documents (newspapers, journal articles, reports, advertisements, posters, etc.), which may have text all over the place. As we can see in the above example, even columns, which intuitively seem like they are regular enough to be picked up, can confound the best OCR models.
Can we do better — and if so, how?
The issue all these models have is not in the accuracy of the text — rather, it is in determining an accurate reading order. Thus, what we have to do is to define a set of pre-processing operations that create and arrange image blocks in a way that returns the correct order when fed through any OCR model.
Grouping text blocks
The first step is to recognize groups of text. Remember, since we only need “blobs” (encoded as bounding boxes) likely to contain text, we need not worry so much about readability, merely distinguishability. We can always pipe the generated coordinates back over the original image for the engine.
To this end, we take advantage of known image manipulation and text segmentation techniques as well as a pinch of graph theory.
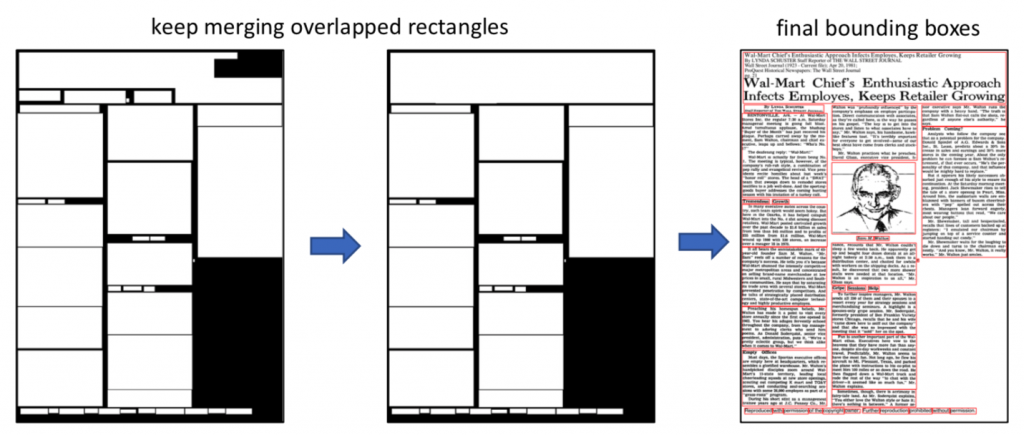
Our process starts by grayscaling and binarizing the image. We do this to transform the image such that all content is black and everything else is white. This is achieved with Otsu’s thresholding, which finds the optimal pixel color decision boundary.

Next, we run the Run-Length Smoothing Algorithm (RLSA) to convert words into “mini-blobs”. We then invert the image and dilate it (add pixels to each mini-blob’s boundaries) until all the mini-blobs sufficiently overlap. From there, we recursively merge together overlapping blobs until no blobs overlap. This ensures each blob represents a distinct content area.

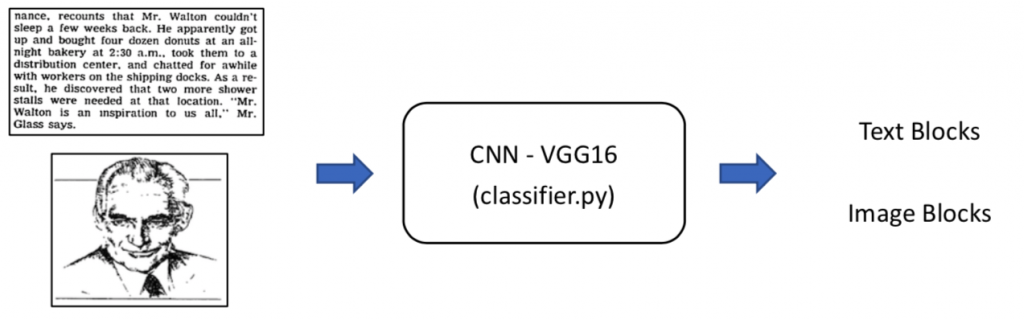
Handling non-text elements
We aren’t done yet, however, because if our document initially had pictures, tables, or graphics, these would be encoded as blobs as well. Thus, we use a classifier, which, when fed in with coordinates of the blob (as applied to the original image), can determine whether it contains text or not. We achieved good results with (at the time) state-of-the-art VGG Net, though any modern architecture will do.
Finally, we have a list of text blobs. Now we must determine their order. To accomplish this, we turn to topological sort, a way of arranging a set of spatially related elements in a reading order. Concretely, we did this by placing blob A before blob B if either 1) they overlap horizontally and A is above B or 2) A is entirely to the left of B and there doesn’t exist a blob C that overlaps both A and B horizontally and vertically.
Finished product
At last, we’re done. We have a list of blobs of text in the order they’d be read. These can be fed into any OCR model of choice to yield a better extraction.
On Google Cloud Vision, this process improved Levenshtein similarity (a measure of how closely two strings match) by 20% on average. It was also fairly fast, only adding a few seconds to the total time spent.
All in all, Tolstoy was able to accurately extract the text from The Wall St. Journal’s historical articles well in time for their 130th Anniversary Special Edition — saving them weeks of tedious manual transcription work, as well as making the text fully digitized and searchable.
Here’s the link to the final published product: https://www.wsj.com/articles/130-years-of-history-as-seen-in-the-pages-of-the-wall-street-journal-11562544331.