AI-Powered
Data Extraction

What Can You Extract?
Tolstoy’s Data Extractor extracts and labels text from virtually any document or record.
Unlike other solutions, we customize an Extractor for each client. Because of this, we are able to process highly unstructured documents — from legal transcripts, to email data, to handwritten records.
OCR
Print and handwriting, structured or unstructured text.
Custom Tagging
Find and label custom types of text. Names, addresses, document numbers, dates, locations, industry-specific terms, etc.
Extract
Extract text from unstructured documents into a structured output: CSV, XLSX, JSON, or other structured format.
Classify
Classify documents, emails, and other records with custom categories.
Customer Success
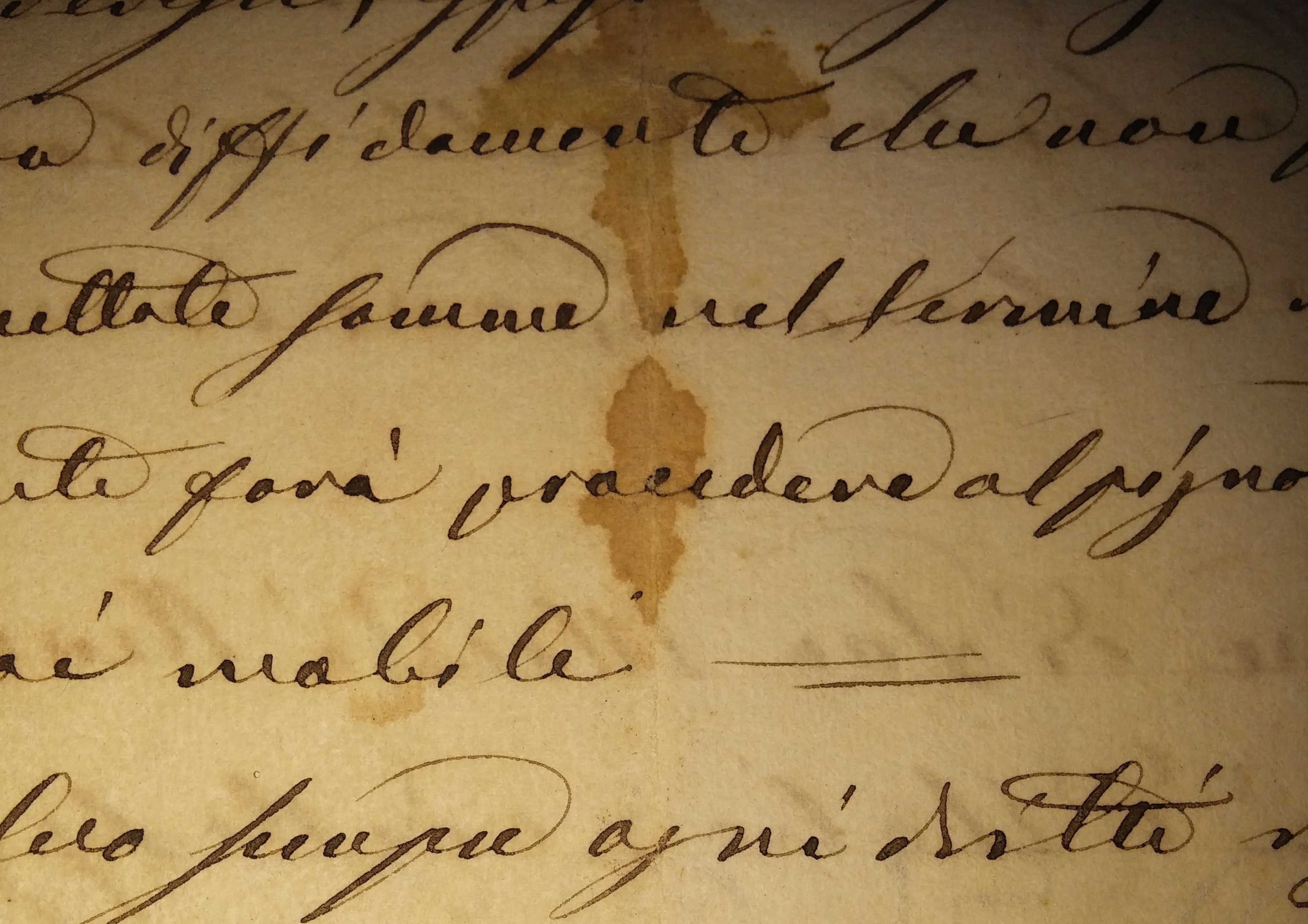
Legal Transcripts
Extract document references from trial dialogue.
Entity Extraction
The university digitized a collection of one million documents from the Nuremberg War Crimes Trial. The contents of the entire collection was unknown, so the university partnered with Tolstoy to help index the documents. This was done by identifying all document references in their 150,000+ pages of court transcripts.
Tolstoy tagged the references with 99%+ accuracy. This saved them approx. 7-8 months of work.
Read more
News clippings
Extract text from old news articles.
Custom OCR
To celebrate their 130th anniversary, The Wall Street Journal wanted to digitize and reprint articles from their entire history in a special edition. Since many of the articles were very old, traditional OCR software did not pick up the text well or at all.
We wrote a custom OCR script that parsed their digitized articles with 95%+ accuracy. This saved them several weeks of manual transcription.
Read more
Maintenance forms
Extract fields from maintenance forms.
OCR and Field Extraction
The New York Power Authority (NYPA) has a critical, 660-megawatt power cable that experienced multiple faults, taking it out of service for 1 to 2 months at a time.
With only disconnected paper documents, NYPA needed one holistic and connected view of the data to properly assess the situation.
Using a customized AI text extraction model, Tolstoy digitized the documents into an Excel database that allowed NYPA to easily view and evaluate the information to determine critical next steps.
Read more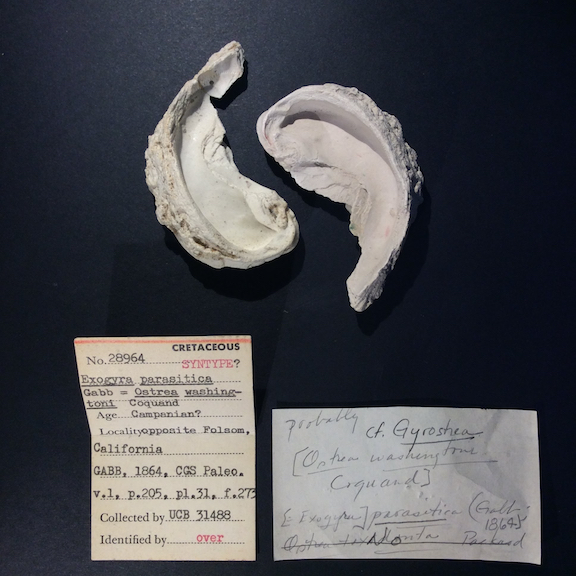
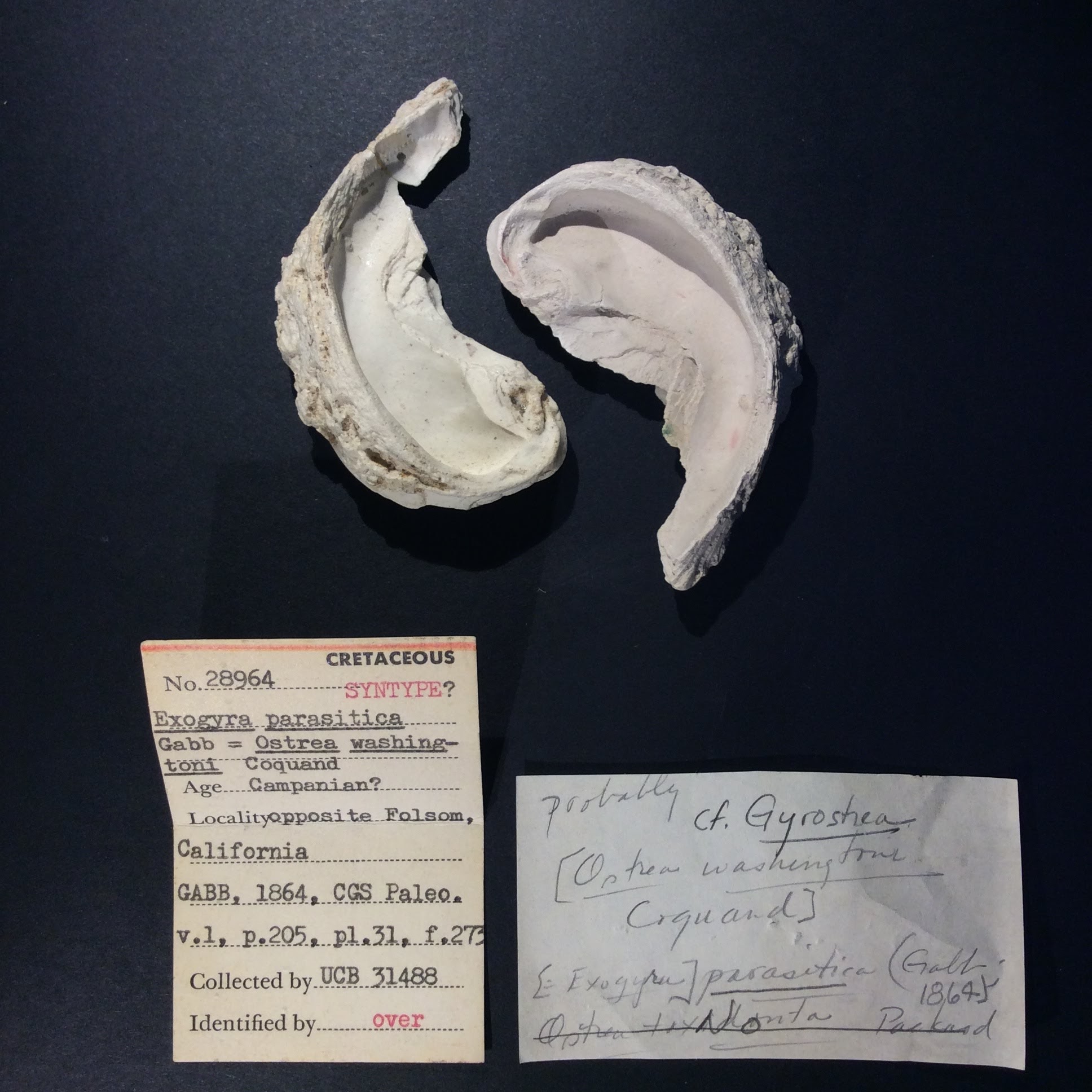
Museum records
Extract fields from handwritten cards.
OCR and Field Extraction
Museums across the world are digitizing their records. This includes extracting text from specimen labels into databases. The labels are often handwritten, with an unknown number of formats. The labels come from various eras, countries, and institutions.
Tolstoy built an Extractor that processes print labels with 98%+ accuracy, and handwritten labels with ~80% accuracy, regardless of the format. This project is ongoing and has the potential to reduce processing times from decades to weeks.
What types of text can be processed?
-
Reports
-
Transcripts
-
Forms
-
Receipts
-
Handwritten labels
-
News articles
-
and more






Automate to Accelerate Data Mastery
Unlock the data in your internal documents, client responses, maintenance forms, and other records. Have a truly complete view of your information. Ensure a strong foundation to track, analyze, and run predictive analytics on your data.
It's your data. Make the best use of it.
Ready to Transform Your Text Workflow?
We'll love to hear about your use case.